

Walking through a 7-barrel brewhouse last month, I watched the head brewer frantically flip through three different notebooks trying to figure out which tank had the IPA that needed dry-hopping. The production calendar on the wall showed one thing, the tank log showed another, and the brewing sheets in his binder contradicted both.
This wasn't a disorganized brewery. They had systems. They had spreadsheets. They had checklists. What they didn't have was a coherent data model that connected batch records to equipment events to inventory movements to quality tests. Every piece of information lived in its own silo.
Building operational software for dozens of breweries has shown me something interesting: the ones that scale successfully aren't the ones with the most sophisticated tracking systems. They're the ones with the simplest, most connected data models that capture exactly what matters and nothing more.
Why brewery data breaks at 500 barrels per month
Small breweries start simple. One brewer, a couple fermenters, handwritten brew logs. Everything lives in the brewer's head. Works fine at 20 barrels a month.
By 100 barrels monthly, cracks appear. The assistant brewer needs access to grain inventory. The packaging team needs to know what's coming out of conditioning. Sales wants to know what's available next week. Everyone creates their own tracking system.
Around 300 barrels, these disconnected systems start causing problems. A batch gets packaged before final gravity is logged. Kegs ship without QC approval. Tank scheduling conflicts because nobody updated the shared calendar.
The breaking point hits around 500 barrels monthly. Manual coordination completely fails. Too many batches, too many SKUs, too many handoffs. The head brewer spends more time hunting for information than brewing. Quality issues slip through because test results aren't connected to batch records. Equipment maintenance gets missed because nobody tracks cumulative usage.
Most breweries respond by adding more tracking. More spreadsheets, more forms, more software tools. This makes things worse. Now the same information lives in five places, all slightly different, none authoritative.
The minimal entities that matter
Six types of records capture everything that matters in a small brewery's operations:
Take control of your brewery’s workflow.
Beeryly helps you schedule batches, track inventory, and monitor sales with ease.
- Production timeline management
- Inventory tracking & alerts
- Sales & distribution monitoring
No credit card required
Batches - The core production unit. Every gallon of beer belongs to exactly one batch. A batch has a brew date, a recipe, target volumes, and moves through your process as a single unit until packaging splits it.
Lots - The packaged output from batches. One batch might become three lots: kegs packaged Monday, cans Tuesday, bottles Wednesday. Lots are what you sell, ship, and recall if needed. Each lot points back to its parent batch.
SKUs - Your product catalog. The IPA in 6-packs, the IPA in kegs, the IPA in 22oz bottles - different SKUs, possibly from the same batch. SKUs define what you sell, lots track what you actually produced.
Orders - Customer commitments. Orders reference SKUs (what they want) and get fulfilled by lots (what you ship). This connection is critical for traceability and inventory accuracy.
QC Tests - Quality control measurements tied to specific batches or lots. pH at knockout, gravity after fermentation, micro results before packaging. Tests must connect to what they're testing.
Equipment Events - Things that happen to tanks, lines, and other equipment. CIP cycles, maintenance, repairs, batch occupancy. Events accumulate to show equipment history and predict maintenance needs.
That's it. Six entity types. Everything else is either an attribute of these entities or a relationship between them.
A Belgian quad aged 8 months doesn't need a special "aging" entity. It's a batch with a long tank residence time. Dry-hopping isn't a separate record type - it's an equipment event on the fermenter. Yeast harvesting connects two batches through a shared attribute.
The magic happens in the relationships. A batch touches equipment (creating events), undergoes tests (creating QC records), becomes lots (through packaging), which fulfill orders (through shipping). Every operational question traces through these connections.
Building your 90-day data capture foundation
Start capturing data before building elaborate systems. Use whatever tools you have - Google Sheets, a notebook, basic software. The structure matters more than the technology.
Days 1-30: Establish batch tracking
Begin with batch identification. Every batch needs a unique ID that follows it from mash tun to package. Format doesn't matter initially - "IPA-2024-03-15" works fine. Consistency and uniqueness matter.
-
Batch ID
-
Recipe name and version
-
Brew date
-
Target volume (BBL)
-
Actual strike volume
-
Original gravity
-
Brewer initials
Don't overthink it. A simple spreadsheet with one row per batch. The goal is creating the habit of recording every batch consistently.
Days 31-60: Add equipment and movement tracking
Track where batches live and when they move. For each batch, record:
-
Mash tun used and duration
-
Kettle used and duration
-
Fermentation vessel and date in
-
Conditioning/bright tank and date in
-
Date to packaging
Add a simple equipment log. For each tank/vessel:
-
Equipment ID
-
Current batch (or "empty")
-
Last CIP date
-
Days since last full maintenance
This reveals actual tank utilization and maintenance gaps. One brewery discovered they were CIPing some tanks twice as often as needed while others went weeks between cleanings.
Days 61-90: Connect packaging, QC and orders
When you package, create lot numbers that reference the parent batch. Format like "IPA-2024-03-15-KG" for kegs, "IPA-2024-03-15-CN" for cans.
For each lot, track:
-
Lot ID
-
Parent batch ID
-
Package date
-
Package type (keg/can/bottle)
-
Unit count
-
Unit size
Start recording QC data against specific batches and lots:
-
Test date
-
Batch/lot ID
-
Test type (pH, gravity, micro, sensory)
-
Result
-
Pass/fail
-
Tester initials
Finally, connect orders to inventory:
-
Order number
-
Customer
-
SKUs ordered
-
Lots shipped
-
Ship date
After 90 days, you'll have enough connected data to see patterns. Which recipes have quality issues? Which tanks need more maintenance? Which SKUs move fastest?
Use a consistent Batch ID format from day one to make joins between tables trivial.
Here's a simple workflow to capture data over the first 90 days.
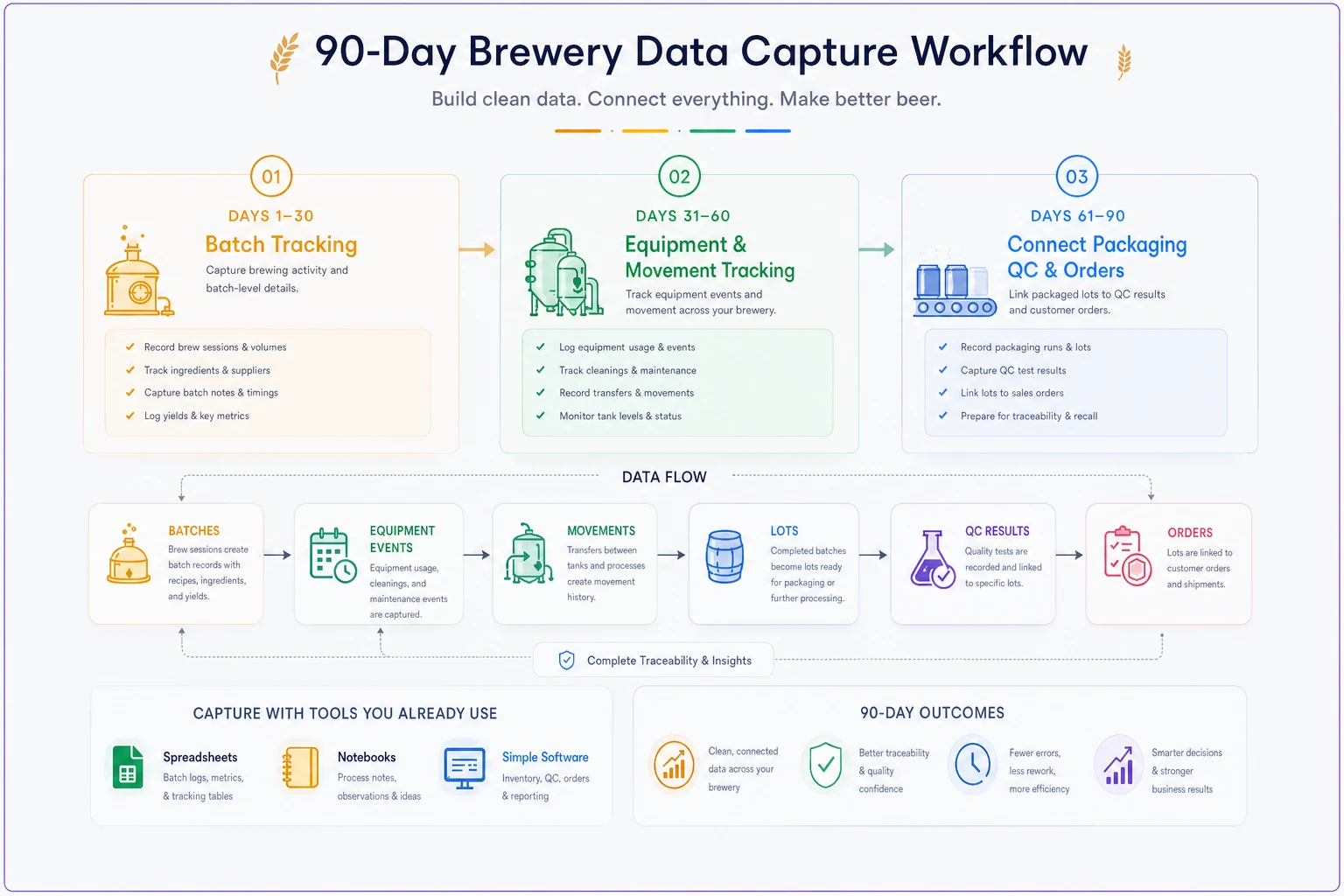
Keep the workflow visible and shared so everyone records consistently.
Sample data structure that actually works
Working example from a 15-barrel brewhouse producing 400 BBL monthly:
Batch Table Structure:
| Batch_ID | Recipe | Brew_Date | Target_BBL | Actual_BBL | OG | Brewer |
|---|---|---|---|---|---|---|
| IPA-240315 | Hazy IPA v3 | 2024-03-15 | 15 | 14.5 | 1.062 | TM |
| LAG-240316 | Pilsner v1 | 2024-03-16 | 15 | 15.2 | 1.048 | JR |
| STOUT-240318 | Milk Stout v2 | 2024-03-18 | 10 | 9.8 | 1.058 | TM |
Equipment Event Log:
| Event_Date | Equipment_ID | Event_Type | Batch_ID | Duration_Hours | Notes |
|---|---|---|---|---|---|
| 2024-03-15 | FV01 | Batch_In | IPA-240315 | - | 14.5 BBL transferred |
| 2024-03-15 | FV02 | CIP | - | 2.5 | Post-Stout cleaning |
| 2024-03-22 | FV01 | Dry_Hop | IPA-240315 | 0.5 | 22 lbs Citra |
| 2024-03-29 | BT01 | Batch_In | IPA-240315 | - | From FV01 |
Lot Creation Records:
| Lot_ID | Batch_ID | Package_Date | Type | Units | Size | Total_BBL |
|---|---|---|---|---|---|---|
| IPA-240315-KG1 | IPA-240315 | 2024-03-30 | Keg | 24 | 0.5 BBL | 12 |
| IPA-240315-CN1 | IPA-240315 | 2024-03-31 | Can | 120 | Case/24 | 2.3 |
QC Test Results:
| Test_Date | Batch_Lot_ID | Test_Type | Result | Spec | Pass |
|---|---|---|---|---|---|
| 2024-03-29 | IPA-240315 | FG | 1.013 | 1.010-1.014 | Yes |
| 2024-03-29 | IPA-240315 | pH | 4.3 | 4.2-4.4 | Yes |
| 2024-03-30 | IPA-240315-KG1 | Micro | 0 CFU | <10 CFU | Yes |
This structure answers critical questions instantly:
What's in FV01 right now? Check equipment events. Which lots came from the March 15 IPA batch? Query lot records. Did we test pH before packaging? Check QC results. How long was the Pilsner in fermentation? Calculate from equipment events.
The relationships matter more than the fields. Every lot knows its batch. Every test knows what it tested. Every equipment event creates a timeline.
Four automated checks that prevent 80% of operational disasters
Manual data entry creates errors, but the right validation rules catch problems before they cascade.
1. Tank occupancy validation
Before accepting any "Batch In" equipment event, check if that tank is actually empty. Double-batching tanks happens more than you'd think.
Simple rule: No tank can have two active batches. When a batch moves in, verify the last batch moved out. One brewery caught three near-misses in their first month just from this check.
The validation looks like:
Check what's the last event for FV01? If it's another batch in without a batch out, flag it. If it's a CIP or empty, allow it.
This also catches forgotten transfers. If a batch supposedly moved from FV01 to bright tank, but FV01 never shows that batch leaving, something's wrong with your records.
2. Volume balance tracking
Beer doesn't multiply. If you brew 15 BBL and package 18 BBL from that batch, you have a data problem.
Track cumulative volume at each stage. Actual brew volume: 14.5 BBL. Into fermenter: Should be ≤14.5 BBL (some loss expected). Into bright tank: Should be ≤14.0 BBL (yeast/trub loss). Total packaged: Should be ≤13.5 BBL (transfer loss).
When lot creation exceeds remaining batch volume, flag it immediately. One brewhouse discovered they'd been double-counting partial keg fills, inflating inventory by 12%.
3. QC test sequence enforcement
Certain tests must happen in order. You can't have a passing final gravity before fermentation completes. You can't release lots before micro results.
Build a simple test dependency chain. OG must exist before FG. FG must exist before packaging. Micro must exist before lot release. Sensory must happen within 3 days of packaging.
When someone tries to enter results out of sequence, require an explanation. Valid reasons exist (re-testing, special circumstances), but forcing documentation catches process shortcuts.
4. Maintenance interval alerts
Equipment events should trigger maintenance counters. After 10 batches or 30 days (whichever comes first), flag tanks for deep cleaning. After 25 CIP cycles, gaskets need inspection.
Track cumulative metrics per equipment. Batches since full breakdown. CIP cycles since gasket replacement. Days since calibration. Total BBL processed lifetime.
When limits approach, generate warnings. When limits pass, require override authorization. One brewery avoided a contamination outbreak by catching a fermenter that hadn't been deep cleaned in 8 weeks.
When your spreadsheet system breaks
Spreadsheets work until they don't. The breaking point usually hits around 700-800 BBL monthly production, or whenever you have more than three people entering data.
Version conflicts everywhere. The production sheet shows one thing, the inventory sheet another, and nobody knows which is current. You spend more time reconciling than recording.
Manual updates cascade forever. Changing a brew date means updating twelve different sheets. Moving a batch between tanks requires seven copy-paste operations. One missed update breaks downstream reports.
Historical data vanishes. You can see current tank contents but not what was there last week. Quality trends are invisible because old test results get overwritten. You can't trace lots back to batches from two months ago.
Calculations break constantly. Formulas reference deleted rows. Pivot tables show #REF errors. Someone "fixed" a formula three months ago and now inventory is off by 400 gallons.
This is when operational software becomes necessary. Not because spreadsheets can't handle the data volume, but because manual coordination between sheets fails. Modern AI-powered platforms can maintain data relationships automatically, validate entries in real-time, and prevent the cascading errors that kill spreadsheet systems.
The key is starting with the right data model from day one. Whether you use notebooks, spreadsheets, or software, the same six entities and their relationships drive everything. Get the structure right early, and upgrading tools becomes straightforward. Get it wrong, and you'll be untangling data problems forever.
Making data drive decisions, not just compliance
Most breweries collect data for compliance - TTB reporting, state requirements, FDA traceability. But the same minimal data model that satisfies regulators can transform operations.
Connected batch and equipment records reveal your actual vs theoretical tank utilization. One brewery discovered their fermenters averaged 70% capacity because partial batches tied up whole tanks. They adjusted batch sizes and increased throughput 20% without adding equipment.
QC data linked to batches and equipment exposes problem patterns. Three failed micro tests, all from the same bright tank, all after weekends. Investigation revealed a temperature controller failing intermittently. The pattern was invisible when test results lived in a separate quality log.
Order and lot connections show true product velocity. Not just what sold, but how long it sat, where it went, and what came back. A farmhouse ale that seemed popular actually had 30% returns - all from lots packaged in summer, all shipped to the same distributor region, all failing at retail.
The minimal model creates these insights because everything connects. You're not just tracking batches - you're tracking batches through equipment over time with quality gates and inventory outcomes. The full lifecycle becomes visible.
Your brewery production scheduling system might prevent timing conflicts, but without connected data, you can't see why certain batches consistently run late. Your operations KPIs might flag problems, but without tracing KPIs back to specific equipment events and batches, you can't fix root causes.
Bottom line: structure beats sophistication
Two years ago, a 10-barrel brewhouse in Denver was drowning in spreadsheets. Seven different tracking systems, none talking to each other. The owner spent Sundays just trying to reconcile inventory.
They stripped everything back to the six core entities. One batch table. One equipment log. One lot tracker. Simple relationships between them. Clear ownership of who updates what.
Today they're running 850 BBL monthly through the same 10-barrel system. Not because they bought fancy software (though they did eventually upgrade from spreadsheets). But because they built the right data foundation first.
The small brewery data model doesn't need to be complex. It needs to be complete, connected, and consistent. Six entity types, clear relationships, basic validation rules. Everything else is details.
Start with structure. Add sophistication later. And remember - even the best data model is worthless if your team doesn't actually record the data. Keep it minimal, keep it manageable, and keep it maintained. That's how scattered records become reliable operations.
Ready to elevate your brewery operations?
Join 500+ craft breweries using Beeryly to increase production efficiency, reduce waste, and grow sales.

